

【この記事でわかること】
- AIが「もっともらしい嘘」をつくハルシネーションの基本的な意味
- ハルシネーションが発生してしまう主な3つの原因
- 日本企業が直面しうる、ハルシネーションによる具体的なビジネスリスク
- 担当者・管理者・組織の立場別で取り組むべき実践的な対策
- ハルシネーション以外の生成AIリスクと、安全に活用するための心構え
監修者 今林氏のコメント
この記事で解説されているハルシネーションは、生成AIを業務で活用する際に最も注意すべきポイントです。重要なのは、これが技術的な「バグ(欠陥)」ではなく、現在のAI技術の仕組み上避けられない現象ということです。 しかし、適切な理解と対策により、このリスクは十分にコントロール可能です。特に「AIを過信しない」「適切な機能を入れる」「必ず人間が最終確認する」という基本原則を守ることで、AIは強力な業務支援ツールとなります。 本記事の対策を実践いただければ、AIのメリットを最大限に活用しながら、リスクを最小限に抑えることができるはずです。
ハルシネーション(幻覚)とは?
AIハルシネーションの基本的な定義と比喩表現の由来
ハルシネーションとは、AI、特にChatGPTのような生成AIが、事実に基づかない情報や文脈に合わない内容を、もっともらしく生成してしまう現象を指します。AIは学習した膨大なデータから、次に来る確率が最も高い単語を予測して文章を作成しますが、そのプロセスで誤った情報を「創り出してしまう」ことがあるのです。
なぜ「幻覚」と呼ばれるのか?AIの挙動を人間心理に例えて理解
この現象が「幻覚(Hallucination)」と呼ばれるのは、その挙動が、人間が存在しないものを見たり聞いたりする「幻覚」に似ているためです。生成AIには悪意があるわけではなく、あくまで確率的な予測の結果として、意図せず誤った情報を生成してしまいます。
その出力は非常に流暢で自然であり、しばしば高い自信(High Confidence)を伴って提示されるため、人間がそれが「嘘」であると見抜くことが難しい点が、この問題の厄介なところです。専門家でさえ、そのもっともらしさ(Plausibility)に騙されることがあります。
【参照URL】
生成AIにおけるハルシネーションの具体的な種類と見分け方
ハルシネーションは、大きく2つの種類に分類されます。それぞれの特徴を知ることで、出力された情報のどこに注意すべきかが見えてきます。

Intrinsic Hallucination(内在的なハルシネーション)
- 概要: AIが学習したデータ(ソース)の内容と矛盾する、または逸脱した情報を生成する現象です。
- 具体例: 「東京スカイツリーの高さは634m」という正しい情報を学習しているにも関わらず、「日本の首都、東京にある東京タワーの高さは634mです」のように、情報の一部を誤って組み合わせて回答するケース。ソースとなる情報自体は正しいにもかかわらず、出力の段階で誤りが生じます。
Extrinsic Hallucination(外在的なハルシネーション)
- 概要: AIが学習したデータには存在しない、全く新しい情報を捏造(ねつぞう)する現象です。
- 具体例: 存在しない判例や学術論文を、もっともらしい概要や著者名と共に引用するケース。これはファクトチェックがより困難で、深刻な問題を引き起こす可能性があります。
AIはなぜ「嘘」をつくのか?ハルシネーションの主要な原因
AIがハルシネーションを起こす原因は、一つではありません。主に「学習データ」「AIモデル」「プロンプト(指示)」の3つの要素が複雑に絡み合っています。
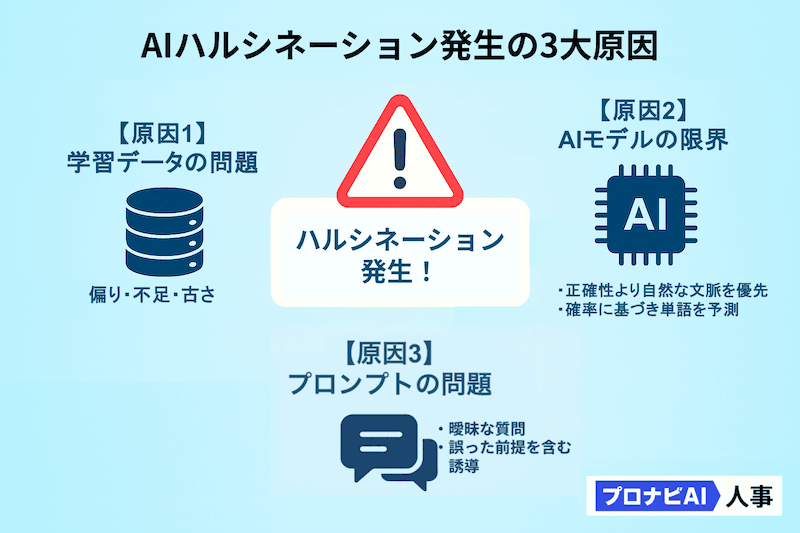
学習データの問題:偏り、不足、古さが招く誤情報
生成AIの知識出力において、学習したデータに下記のような問題があると、ハルシネーションが発生しやすくなります。
- データの偏り: 特定の分野や年代の情報に偏ったデータを学習すると、AIの知識も偏ります。
- データの不足: 専門的領域や最近の出来事など、データが不足していると、確率頻度の高い一般論や過去によく参照された出来事の単語を拾おうとして誤りを犯します。
- データの古さ: AIの学習データは、ある特定の時点までのものです。そのため、最新の情報(法改正、新サービスの登場など)を尋ねても、古い情報に基づいて回答してしまうことがあります。
AIモデルの構造的問題:確率的推論が落とし穴に
生成AI(大規模言語モデル)は、「次に来る単語の確率」を予測することに特化しています。
より正確に言えば、入力された文章を細かい単位(トークン)に分割し、それらの関連性を数値ベクトルとして計算(エンコード)し、次に続く確率が最も高いトークンを予測して出力(デコード)する、という処理を繰り返しています。
このため、モデルは「真実」を理解しているのではなく、また膨大な個々の文章を「暗記」しているわけでもなく、学習に活用した文章(学習データ)の中で、どの単語の組み合わせパターンや関係性が最も多かったか・少なかったかを計算しているに過ぎません。
つまり、生成AIは確率的な予測の連鎖により、統計的に「ありそう」な文章を生成しているだけなのです。その過程で、”マジカルバナナ”のように学習データに存在しない単語の組み合わせも確率的に生成してしまうことから、結果的に事実ではない回答を生成してしまうのです。
【参照URL】
監修者 今林氏のコメント
今後、基本的なLLMに対して、話の流れ/流暢さ/自然さを評価・学習する仕組みが組み込まれると、より人間がハルシネーションに気づけなくなるリスクがあがりますね。実際にその隙間をついたAI詐欺やAIサイバー攻撃なども出てきていますので、要注意です。
プロンプト(指示)の与え方:曖昧さや誘導がハルシネーションを誘発
AIへの指示である「プロンプト」も、ハルシネーションの引き金になります。
- 曖昧なプロンプト: 「日本の経済について教えて」のような曖昧な質問をすると、AIの”知識探索空間”を絞ることができず(どの側面に焦点を当てるべきか判断できず)、一般的で当たり障りのない回答を生成しがちです。
- 誤った前提を含むプロンプト: 「Apple社が開発したWindows OSについて説明して」のように、誤った前提を含む質問をすると、AIはその前提に乗っかって、Apple社に関連する単語群とWindows OSに関連する単語群を掛け合わせ、もっともらしい嘘の回答を組み立ててしまうことがあります。
監修者 今林氏のコメント
これってもう、使う側のリテラシーの問題になってきますよね。誤った情報を人がインプットするってことは、人がすでに幻覚を起こしちゃってるってこと。これは「幻覚の連鎖」とも呼べる現象で、人間の幻覚 × AIの幻覚 = 複合的な虚構世界、最終的な出力は現実から大きく乖離した内容になってしまうのです。だからこそ、プロンプトを作成する段階から、事実関係の確認が重要となりますね。
ハルシネーションが招く現実世界のリスクと日本企業への影響
ハルシネーションは、単なる「AIの言い間違い」では済みません。ビジネスの現場では、企業の信頼性や業績に直結する深刻なリスクとなり得ます。
社会的な誤情報の拡散とブランドイメージの毀損
企業がAI生成コンテンツを十分に確認せず発信した場合、誤情報が拡散され、社会的な混乱を招く恐れがあります。
象徴的なのは、2023年にGoogleが発表したAI「Bard」(現Gemini)の事例です。
デモンストレーションで「ジェイムズ・ウェッブ宇宙望遠鏡(JWST)がもたらした新発見は?」という質問に対し、Bardは「JWSTは太陽系外惑星の写真を史上初めて撮影した」と回答しました。しかし、これは事実誤認であり、この誤りが報道されると、Googleの親会社であるAlphabet社の株価は一時、前日比9%近く下落しました。
この一件は、たった一つのハルシネーションが、企業の市場価値やブランドイメージをいかに巨大な規模で毀損しうるかを示しています。
【参照URL】
一度「不正確な情報を流す企業」というレッテルを貼られてしまうと、築き上げてきたブランドイメージや信頼を回復するには、多大な時間とコストがかかります。
ビジネス上の誤った意思決定と経済的損失事例
経営層や管理職が、AIが生成した市場分析レポートや競合調査の結果を鵜呑みにして意思決定を下した場合、どうなるでしょうか。市場機会の損失や、誤った投資による経済的損失に直結する可能性があります。
法曹界では、さらに深刻な事態が発生しています。2023年、米国の弁護士が航空会社に対する訴訟で、準備書面にChatGPTが生成した「実在しない過去の判例」を複数引用してしまいました。これは、AIの出力を無批判に信頼した結果であり、裁判所はこの弁護士と所属法律事務所に対し、制裁金を科すという厳しい判断を下しました。
この事件は、AIの利用が専門家に課せられる「合理的な調査」の義務を免除するものではないことを明確に示しました。
【参照URL】
ハルシネーションを徹底的に防ぐ!実践的な対策と運用ノウハウ
そもそも確率的であること、使う人のリテラシーに依存することから、ハルシネーションを100%なくすことは困難ですが、リスクを大幅に低減させることは可能です。ここでは「開発者・管理者」「利用者」「組織」の3つの視点から、具体的な対策を紹介します。
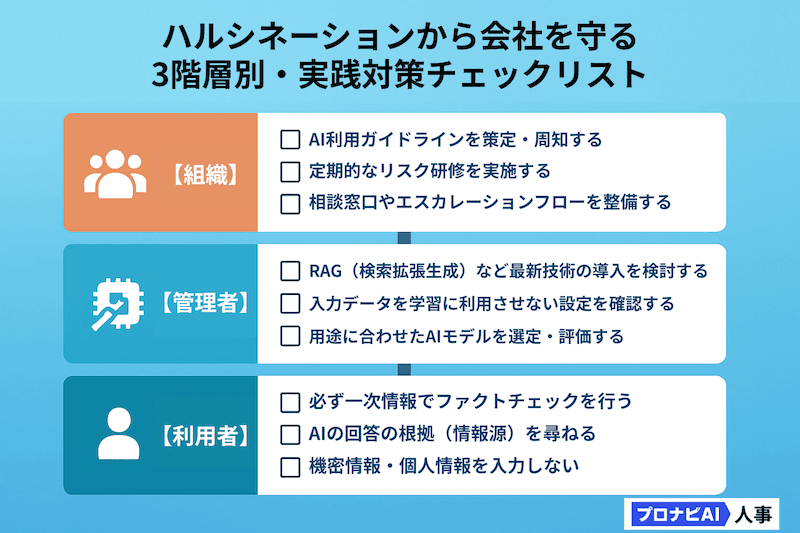
【AI開発者・管理者向け】モデルと学習データの改善策
AIシステムを提供する側、あるいは自社でAIモデルを管理する立場にある方向けの技術的な対策です。下記の統合的なアプローチを実施することで、技術的な対策だけでなく、組織全体でハルシネーションリスクを管理できる体制が構築できます。
- 防御的設計で、そもそもハルシネーションが起きにくい環境を作る
- 高品質なデータベースで、正確な情報源を確保する
- 業務特化型RAGで、文脈に応じた適切な情報を提供する
- フィードバックループで、継続的に精度を向上させる
- 用語の標準化で、誤解や曖昧性を排除する
1. 利用者のリテラシーに依存しない防御的設計
なぜ重要か:どんなに優秀なAIシステムも、利用者の使い方次第で危険なツールになりえます。具体的な実装例としては、下記をご参照ください。
- 誤った前提を含む質問を検出し、警告を表示するような(例:「2025年のノーベル賞受賞者は?」→「未来の情報は提供できません」)入力検証ができる機能の実装
- 固有名詞や数値が含まれる回答には自動で「要確認」フラグを付与したり、信頼度スコアの表示(高/中/低)により、自動的な事実確認ができる機能の機能
- 初級ユーザーには「事実確認済みの情報のみ表示」、上級ユーザーには「推論を含む回答も許可」のような段階的な権限設定の実装
2. 信頼できる参照データベースの設計と管理
なぜ重要か:RAGの効果は、参照するデータの質に100%依存します。データベースの仕様・詳細設計は本題とはずれますので、あくまで一般レベルの考え方の具体例を記載します。
- 参照するデータに優先度(重みづけ)を付与したり、除外対象を明確にすることが重要です。コーポレート系データでは例えば、例えば下記の設定の機能実装が想定できます。
- 優先度1:「公式文書(法令、社内規程、製品仕様書)」
- 優先度2:「検証済みマニュアル、FAQ」
- 優先度3:「過去の対応履歴(成功事例)」
- 除外対象:「未検証の情報、個人の意見、古いバージョンの文書」データ管理の観点では、例えば下記のような設定・機能を実装できます。情報の鮮度管理:「文書には必ず「最終更新日」「有効期限」を設定バージョン管理:古い情報が誤って参照されないよう時系列を管理責任者の明確化:各文書に「情報責任者」を設定するよう管理(定期レビューを義務化する運用とセット)
- データ管理の観点では、例えば下記のような設定・機能を実装できます。
- 情報の鮮度管理:「文書には必ず「最終更新日」「有効期限」を設定
- バージョン管理:古い情報が誤って参照されないよう時系列を管理
- 責任者の明確化:各文書に「情報責任者」を設定するよう管理(定期レビューを義務化する運用とセット)
3. 業務特化型RAGシステムの構築
なぜ重要か:汎用的なRAG(Retrieval-Augmented Generation: 検索拡張生成)では、業務特有のニュアンスを捉えきれません。RAGは、AIが答えを生成する前に、関連する情報をデータベースや文書から検索して一時的に保管する仕組みで、厳密な表現ではないですが”短期記憶的”な使い方が特性を発揮しやすいものです。そのため、業務特化で各個別業務にそれぞれ実装することをおすすめします。
イメージとしては、次のような多段階検索としての実装例をご参照ください。
- まずは、社内データベースを検索(上記の「2」を参照)
- 該当なしの場合、信頼できる外部情報や次の優先度をもったデータベースを検索
- 検索結果をRAG特有のフォーマットで(短期記憶として)保管しつつ、その情報を生成AI(LLM)に流して、回答生成を補助する。
なお、3の際には、見つかった情報には、引用元を引っ張るようにすると信頼性が高い実装になります。全ての回答に「参照元:○○マニュアル p.23」のような具体的な出典を付与し、不明な場合は「情報不足」として明示すると、利用者は判断しやすいです。
4. 継続的改善のためのフィードバックループ
なぜ重要か:静的なシステムでは、新しいハルシネーションパターンに対応できません。
フィードバックシステムの構築イメージとして下記をご参考ください。
- ワンクリック評価:回答ごとに「正確/不正確」ボタンを設置
- 詳細フィードバック収集:□ 事実と異なる □ 古い情報 □ 誤解を招く表現 □ その他(自由記述)
- 自動分析サイクル:評価やフィードバックを元に、フィードバックの集計と分析、頻出する誤りパターンの特定と対策、などを行えると良いシステムになります。
5. 組織固有の用語集とオントロジーの構築
なぜ重要か:同じ言葉でも、組織や文脈によって意味が異なります。構築イメージとして下記をご参考ください。
- 用語集の自動適用:AIが回答生成時に、自動的に組織固有の定義を参照
- 曖昧性の排除:複数の意味がある用語は、表示、文脈から重みづけ
- 新語の登録フロー:現場から新しい用語や定義の追加要請を受け付ける仕組み
監修者 今林氏のコメント
直近2年で、生成AIの実証実験(PoC)に取り組まれる企業も急増しています。よくあるPoC失敗の理由は、上記の何らかの要因が満たせてないケースがほぼ全てです。一度失敗すると、組織内の生成AI活用ムードに大きな負の影響を与えることも少なくなく、失敗された企業からよくご相談をうけます。専門的に込み入った部分ではありますが、こだわって監修しました。生成AI活用に際して非常に重要なポイントですので、ぜひご参考にいただければと思います。
【AI利用者・一般社員向け】出力情報の確実なファクトチェックと見極め方
AIを日々の業務で利用する全ての人が、今すぐに実践できる対策です。
情報源の多重確認とクロスパブリケーション
AIの回答は、そのまま鵜呑みにせず、自分の方がリテラシーが高いんだというスタンスで、参照する程度にとどめてください。必ず一次情報や信頼できる複数の情報源で裏付けを取ってください。 特に、数値データ・固有名詞・法律に関する情報は、官公庁のウェブサイトや専門家の記事などでファクトチェックを徹底することが重要です。
プロンプトで「情報の根拠となるURLを提示してください」と指示することや、「ステップ・バイ・ステップで考えて」と指示して推論の過程を可視化させ、論理の飛躍がないかを確認することも有効な手段です。
【参照URL】
不自然な表現や自信過剰な回答への注意喚起
ハルシネーションによる回答は、時に過度に自信に満ち溢れた表現になることがあります。「間違いなく~です」「絶対に~です」といった断定的な表現が出てきた場合は、一度立ち止まってその根拠を疑う癖をつけましょう
情報の鮮度と文脈の整合性を常に意識する
AIがいつの時点のデータで学習したかを意識し、最新の情報が求められるタスクでは特に注意が必要です。また、質問の文脈から大きく外れた回答や、話の辻褄が合わない部分がないかを確認することも大切です。
【組織全体向け】AI利用ガイドラインの策定と社員教育の徹底
個人の努力だけに頼らず、組織としてAIと向き合う体制を構築することが、リスク管理の鍵となります。
禁止事項と推奨事項を明確化したガイドラインの作成
全社員が遵守すべきAI利用のルールを明確に定めましょう。 ガイドラインには、一般的に以下のような項目を盛り込むことが推奨されます。
- 入力禁止情報: 個人情報、顧客情報、社外秘の情報の入力を禁止する。
- 利用範囲: AIを利用して良い業務、禁止する業務を明確化する。
- ファクトチェックの義務化: AIの生成物を業務利用する際の確認プロセスを定める。
- AI生成物の明記: AIが生成した文章や画像を公開する際に、その旨を明記するルールを設ける。
定期的なハルシネーションリスク研修の実施
ガイドラインを作成するだけでなく、全社員を対象に、ハルシネーションのリスクや具体的な対策を学ぶ研修を定期的に実施し、組織全体のリテラシーを向上させることが不可欠です。
ハルシネーション以外の生成AIリスクと包括的な対策
ハルシネーション対策は重要ですが、生成AIのビジネス活用には他にも注意すべきリスクが存在します。
情報漏洩とセキュリティリスク:AI利用時のデータ管理の重要性
プロンプトとして入力した情報が、AIモデルの学習データとして再利用され、意図せず他のユーザーへの回答に含まれてしまう可能性があります。
機密情報を入力しないという基本ルールを徹底し、必要であれば入力データを学習に利用しない設定が可能な、法人向けサービスを利用することが重要です。
倫理的問題と著作権侵害:法令遵守と責任範囲の明確化
AIが生成したコンテンツが、既存の著作物を無断で複製・改変している可能性もゼロではありません。
生成物を商用利用する際は、著作権侵害のリスクがないかを確認する必要があります。また、ハルシネーションによって特定の個人の名誉を毀損する情報を生成してしまった場合、法人としての法的責任を問われる可能性もあります。AIの利用に関する倫理的な方針を定め、社会的責任を果たす姿勢が企業には求められます。
AIシステム全体の品質保証の必要性
ハルシネーションは、AIシステムにおける品質問題の一つに過ぎません。出力の安定性、セキュリティの脆弱性、特定のバイアスなど、多角的な視点からAIシステムの品質を評価し、管理していく体制が求められます。
まとめ:ハルシネーションと向き合い、AIを真の「パートナー」に
本記事では、生成AIのハルシネーションについて、その原因からビジネスリスク、そして具体的な対策までを解説しました。ハルシネーションは、AIを業務で活用する上で避けては通れない課題です。しかし、その特性を正しく理解し、適切な対策を講じることで、AIは私たちの業務を劇的に効率化し、創造性を高めてくれる強力なパートナーとなり得ます。
AIの回答を盲信するのではなく、あくまで優秀な「アシスタント」として捉え、最終的な判断と責任は人間が担うこと。この原則は、AIと人間との間に存在する「オートメーション・バイアス(自動化バイアス)」を乗り越えるために不可欠です。オートメーション・バイアスとは、自動化されたシステム(AI)からの情報を過度に信頼し、無批判に受け入れてしまう人間の心理的な傾向を指します。
弁護士のような専門家でさえハルシネーションに気づけなかった背景には、このバイアスの影響があります。AIが流暢な回答を生成することで、人間は本来行うべき検証プロセスを省略してしまうのです。この心理的な罠を自覚することが、安全なAI活用の第一歩となります。

