
【まず結論】生成AIに個人情報を『入れてはいけない』のか?
人事部門の皆様がまず知りたいのは、「結局、履歴書や評価データなどの個人情報をAIに入力していいのか?」という点でしょう。
結論として、氏名や住所など個人を直接識別できるデータを、規約を確認していない一般向けサービス(例:無料版ChatGPTなど)へ入力するのは避けるべきです。
個人情報を入力する行為は、個人情報保護法に抵触する可能性があるほか、入力内容が学習や出力に再利用され情報漏洩を招く恐れがあります。リスクを過度に恐れる必要はありませんが、「回避の方法」を理解し運用することが、安全かつ効率的な活用の第一歩です。
なぜリスクがある?個人情報漏洩の3つの要因
生成AIサービスに入力した情報が漏洩する要因は、技術的な側面とルール運用の側面に分けられます。
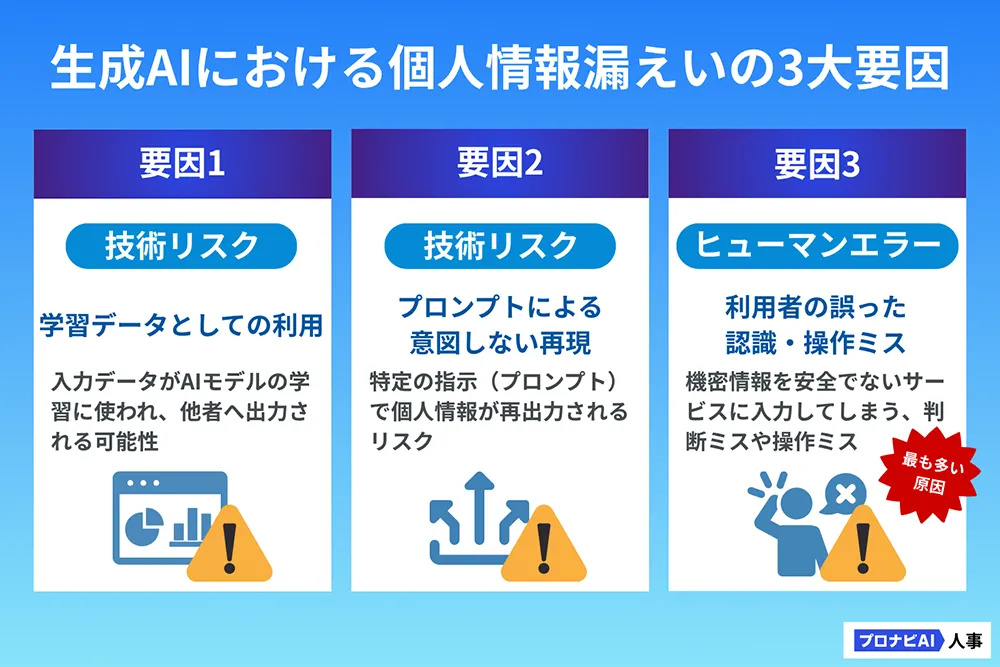
【学習データとしての利用】
多くの無料・一般公開されている生成AIサービスでは、入力されたデータがAIモデルの性能向上のための「学習データ」として利用される可能性があります。これにより、他ユーザーへの応答に自社の機密情報や個人情報が含まれてしまうリスクが生じます。
【プロンプトによる意図しない再現】
AIモデルが学習データとして取り込んだ個人情報の一部が、特定のプロンプト(指示)によって意図せず再現され、他者に出力されてしまう「データ漏洩」のリスクがあります。
【利用者の誤った認識・操作ミス】
これが最も多い原因です。「これは機密情報ではないだろう」という利用者の誤った判断や、機密情報を安全ではないモードで入力してしまう操作ミスなど、ヒューマンエラーによる情報漏洩です。
人事・採用担当者が特に注意すべき個人情報とは

人事・採用担当者が日常的に扱うデータの中で、生成AIへの入力時に特に高いリスクを伴うのは以下のデータです。
| データの種類 | 具体的なデータ例 | 漏洩した場合の重大性 |
|---|---|---|
| 採用・選考情報 | 履歴書(氏名、住所、電話番号、学歴)、職務経歴書、面接評価データ、不採用理由 | 企業の信頼失墜、個人情報保護法違反(賠償リスク) |
| 社員情報 | 給与情報、健康診断結果、人事評価データ、所属部署 | 従業員からの訴訟リスク、労使関係の悪化 |
| 機密性の高い情報 | 新規事業計画、特許情報、M&A関連情報 | 競争優位性の喪失、不正競争防止法違反 |
特に履歴書や職務経歴書に記載されている「応募者の個人情報」は、絶対にそのまま外部AIに入力してはいけません。 利用目的外の利用にあたる可能性があり、個人情報保護法に抵触するリスクがあります。
【教訓】企業・公的機関で実際に発生した情報漏洩の事例2選
生成AIの活用において、「入力してはいけない情報を入力する」というヒューマンエラーや、「AIサービス側のシステム的な脆弱性」がいかに重大な問題を引き起こすかを示すトラブルは既に発生しています。
1. 公的機関職員による機密性の高い個人情報保護規定違反
- 概要:オーストラリア州ヴィクトリアの子ども保護機関(DFFH)の職員が、保護申立書類の作成支援のためChatGPTを利用した際に、保護対象児童や関係者の個人情報、機密性の高いケース記録を入力。
- 発生したリスク:この行為は、公的機関の個人情報保護規定に違反し、外部AIへのデータ送信を通じて個人情報漏洩リスクを発生させ、結果的に組織への不信感を招いた。
- 教訓:公的な業務文書や機密性の高い個人情報を扱う担当者が、「業務効率化」を目的に安易に外部AIを利用した結果、利用者側の規定違反につながった。
2. OpenAI が ChatGPT 利用者の個人情報を誤表示・流出させたバグ
- 概要:2023年3月、ChatGPTを提供するOpenAIにおいて、システムのバグにより、一部の有料プラン(ChatGPT Plus)のユーザーの氏名、メールアドレス、クレジットカード情報の下4桁などが、他ユーザーのチャット履歴に誤って表示されるインシデントが発生。
- 発生したリスク:このシステム側の予期せぬ不具合(バグ)が、AIサービスのユーザー自身の個人情報流出に直結する危険性を示した。企業利用の場合、従業員の有料アカウント情報が漏洩するリスクも伴う可能性もある。
- 企業が行った対応:OpenAI社は、影響範囲の特定とバグの修正を迅速に行い、システムのセキュリティ強化を図った。
これらの事例は、利用者側のヒューマンエラーとシステム側のセキュリティリスクの両面があり、人事部門が主導する厳格なルール設定と利用環境の整備が不可欠であることを示しています。
情報漏洩を防ぐ『社内ルール構築』3つの必須ステップ
リスクを避け、AIのメリットを享受するために、人事部門が主導すべきは「AI利活用のルール作り」です。ここでは、具体的なルール構築のステップをご紹介します。
ステップ1:『入力禁止データ』の明確化と社員への周知
まずは「何をやってはいけないか」という基準を明確にすることが、現場の迷いをなくし、情報漏洩を防ぐ最善策となります。
- 全社共通の「機密情報・個人情報の定義」を確認:法務部門や情報システム部門と連携し、全社としてAIへの『機密性レベル3以上のデータは絶対に入力禁止』など、具体的なレベル設定を行います。
- 人事部門特有の禁止リストの作成:前述の「人事・採用担当者が特に注意すべき個人情報」に基づき、「未内定の応募者の履歴書原文」「現社員の給与明細データ」など、具体的な文書名を挙げて禁止リストを策定します。
- 利用ツールの明記と利用方法の制限:許可されたセキュアなAIサービス(例:データが学習に利用されないことを保証しているエンタープライズ版など)以外は、個人情報の入力自体を禁止します。
ステップ2:情報漏洩リスクをゼロにするAIサービスの選び方
安全にAIを活用するためには、利用するAIサービスの機能と利用規約を厳しくチェックすることが不可欠です。
【チェックすべき3つの基準】
- 「入力データが学習に利用されないこと」の明記:最も重要です。利用規約やプライバシーポリシーに「入力データは学習に利用しない」旨が明記されているサービスを選びましょう。
- データ保存期間と自動削除の仕組み:入力したデータがどの程度の期間保存され、どのように削除されるかを確認します。
- セキュリティ認証の有無:ISO 27001(情報セキュリティマネジメントシステム)やSOC 2レポートなどの第三者認証を取得しているかを確認し、信頼性の高いサービスを選択します。
ステップ3:『秘匿化・匿名化』を徹底するプロンプト活用術
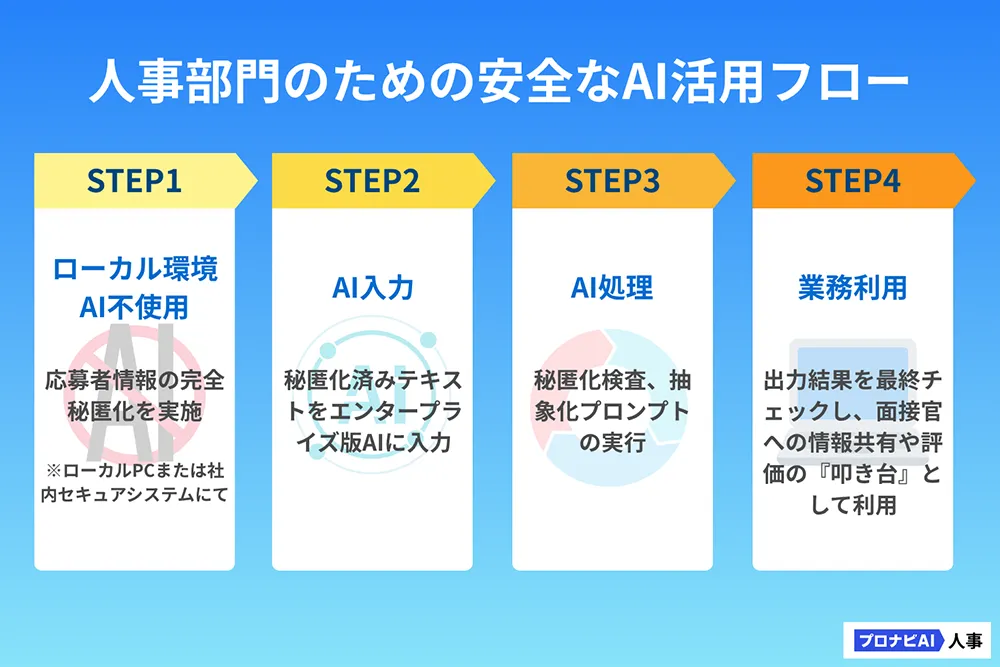
【大原則】AIに入力する前に、人が完全に秘匿化をする
AIに機密性の高いデータをそのまま入力することは厳禁のため、まずはAIを使わずにローカル環境で秘匿化・匿名化を行い、その後に生成AIで処理します。
秘匿化とは、特定の個人を識別できる情報(氏名、住所、具体的な企業名など)をマスキング(例:A氏、〇〇県)したり、削除したりすることです。この処理は、AIに入力する「前」に、手作業または自社開発・セキュアな別システムで行うことが、情報漏洩リスク回避の鉄則です。
安全な秘匿化データ(氏名、住所、電話番号、具体的な在籍企業名を完全に削除したテキスト)が準備できたら、以下のプロンプトを活用し、業務を効率化できます。
| ステップ | 目的 | 手順・コピペOKプロンプト例 |
|---|---|---|
|
STEP1:ローカル秘匿化(AI非使用・必須) |
AI投入前に個人識別子を除去し、ファイルを安全化する | - ローカル(社内端末/社内DLPツール/スクリプト)で、氏名・住所・生年月日・電話・メール・学籍/社員番号・具体的な企業名/案件名を「応募者X」「〇〇県」「19XX年1月1日」「会社A」「案件α」などへ一括置換。 - 応募者IDを採番し、対応表は社内の安全領域にのみ保管。 - 監査ログ(実施者・日時・置換ルール)を記録し、秘匿化済みテキストを作成。 |
| STEP2:AIでの秘匿化検査(二重ガード) | ローカル秘匿化の漏れをAI側で検出する ※エンタープライズ設定(学習不使用・ログ無効・アクセス制御)を満たす場合のみ実施。 |
プロンプト(コピペOK) あなたは個人情報保護の監査官です。以下のテキストに、氏名/住所/電話/メール/生年月日/学籍・社員番号/具体的な企業名・案件名など個人を特定し得る情報が残っていないか網羅的に検査してください。テキスト本文は再出力しないでください。見つかった場合は「開始位置–終了位置・項目種別・置換例」だけをJSON配列で返し、分析には進まないでください。 テキスト:<<<ここに秘匿化済みテキスト>>> |
| STEP3:AIでの抽象化(分析用整形) | 特定回避のため表現を一般化し、分析に適した要約へ整形 |
プロンプト(コピペOK) 検査済みテキストに基づき、「応募者X」の職務経歴を抽象化して要約してください(200字以内)。企業名・固有名詞は伏せ、例:「BtoB SaaSでの営業経験5年」のように一般化した表現で要点を整理してください。 |
| STEP4:業務利用へ | 出力結果を最終チェックし、面接官への情報共有や評価の『叩き台』として利用 | ー |
AIに入力するのはSTEP1で作成した秘匿化済みテキストのみです。機密データ(健康情報・要配慮情報・懲戒等)はSTEP1で止める運用を推奨します。可能であれば、STEP2では短い断片に分割して検査するとリスクをさらに低減できます。
【コピペOK】人事部門のための生成AI利活用ガイドライン
社内利用ガイドラインをゼロから作る必要はありません。情報システム部門や法務部門と連携し、以下の雛形を叩き台として作成しましょう。人事部門が主導すべきは、この『ガイドラインの運用と従業員教育』です。
生成AI利活用ガイドラインの記載必須項目と雛形
1. 基本方針(利用の目的と原則)
- 利用目的:生産性の向上と業務効率化に限定する。
- 原則:個人情報、機密情報、著作権侵害の恐れがある情報は絶対に入力しない。
【重要】秘匿化・匿名化を完了していないデータは、機密情報として扱う
2. 入力データの制限(禁止事項)
- 絶対禁止:応募者の氏名、住所、電話番号、生年月日、具体的な給与額、社員の健康情報など、特定の個人を識別できる情報すべて。
- 禁止の例外:秘匿化・匿名化の処理を施し、誰のデータか特定できない状態に加工したデータのみ利用を許可する。
3. 利用サービスと設定
- 利用推奨サービス:会社が承認し、データが学習に利用されないことが保証されている『エンタープライズ版AI』のみとする。(例:〇〇社の△△AIサービス)
- 設定の義務:個人設定において、『チャット履歴の保存をオフ』にすることを全従業員に義務付ける。
【実例】採用業務で安全にAIを活用する具体的な流れ
採用業務における具体的な安全活用の流れは以下の通りです。
- 情報の受領と初期対応:応募者から履歴書(PDF)を受領する。
- データ加工(秘匿化):手動、またはオフライン社内ツールで氏名、連絡先、企業名などの特定情報を削除し、「応募者Xの職務経歴データ(匿名)」というテキストデータを作成する。
- AIへのプロンプト入力:前章のステップ3で紹介したような「秘匿化・抽象化プロンプト」を用いて、要約やスキル分析をAIに指示する。
- 出力結果の確認:AIの出力結果に個人情報や機密情報が含まれていないかを最終チェックする。
- 業務利用:出力された要約や分析結果を、面接官への情報共有や評価シートの『叩き台』として利用する。
この流れを徹底することで、リスクを最小限に抑えながら、履歴書分析にかかる時間を劇的に短縮できます。
生成AI利活用ガイドラインの策定についてはこちらの記事でより詳しく解説しています。
個人情報保護法と委員会が示す『AI利用の指針』
AI活用に際しては、個人情報保護法と個人情報保護委員会(PPC)の指針(*1)を理解しておくことで、「このガイドラインなら問題ない」という確信をもって社内規定を運用できます。
違反するとどうなる?人事として知っておくべき法的リスク
個人情報保護法は、「個人の権利利益の保護」を目的としており、個人情報を取り扱う事業者が守るべきルールを定めています。
| 法的リスクの種類 | 概要 | 人事部門への影響 |
|---|---|---|
| 利用目的の制限違反 | 応募者から「採用選考」目的で取得した個人情報を、別の目的(例:AIの性能評価)に利用すること。 | 法令違反となり、PPCからの指導・命令の対象となる。 最悪の場合、懲役または罰金(法人には最大1億円 *2)が科される可能性がある。 |
| 安全管理措置義務違反 | 個人情報漏洩を防ぐために必要な措置(社内ルール、アクセス制限など)を講じなかったこと。 | 損害賠償請求(民事訴訟)の対象となる。企業の社会的信頼は失墜し、担当者・管理者としての責任も問われる。 |
人事担当者は、「利用目的を明確にし、その目的の範囲内で利用する」という基本原則を絶対に守る必要があります。
「学習」と「利用」:データ活用の仕組みを人事目線で解説
個人情報保護委員会は、生成AI事業者が個人情報を扱う場合について指針を示しており、特に「学習段階」と「生成・利用段階」の2つのフェーズで法的な注意点を整理しています。(*1)(*3)
- 学習段階:AIモデルを構築するためにインターネット上のデータなどを収集・利用するフェーズ。
- 人事部門への影響:自社がAIサービスを『利用する側』である限り、この学習段階で利用者の個人情報が使われないか(前述のステップ2のサービス選定基準)が重要となります。
- 生成・利用段階:ユーザーがプロンプトを入力し、AIが回答を生成するフェーズ。
- 人事部門への影響:このフェーズで個人情報を入力することは、「利用目的の制限」や「安全管理措置」の観点から問題になります。『秘匿化・匿名化の徹底』は、この利用段階における安全管理措置の一つとして非常に有効です。(*1)
参考・出典:
*1:個人情報保護委員会(PPC)生成AIサービスの利用に関する注意喚起等について
