...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
TOP 人事TOP 記事一覧 生成AIに個人情報を入力するのは情報漏洩リスクにつながる?匿名化・非学習・法人契約による対策も徹底解説 見る、学ぶ、実践する。
イベント・セミナー動画が見放題
プロナビAIの無料会員登録で、話題のイベントやセミナー動画が見放題。
話題のイベント・セミナーのアーカイブ動画をいつでも視聴 すぐに使える実践的なプロンプト集・テンプレートを限定公開 最新のAI活用術をまとめたメールマガジンを毎週お届け 生成AIに個人情報を入力するのは情報漏洩リスクにつながる?匿名化・非学習・法人契約による対策も徹底解説 この記事は約15分で読めます 2025年11月13日 生成AIの登場により、資料作成、メール対応、データ分析などの日常業務は大幅に効率化されつつあります。一方で、多くの企業がAI活用に踏み切れない背景には、「機密情報や個人情報の漏洩リスク」への懸念が存在します。これは企業の信頼性を左右する重要なセキュリティ課題です。
本記事は、日常業務でAIを扱うすべてのビジネスパーソンに向けて「何を、なぜ、どのように避けるべきか」を明確にし、安全なAI活用の具体的なルール、想定されるリスク事例、組織としての対策を網羅的に解説します。
目次 日々の業務で「個人情報・機密情報」を入力しないためのルール AI活用の大きな課題は、「何を入力してはいけないのか」という判断基準の曖昧さです。特にスピードが求められる日常業務において、毎回確認していては、AIの処理スピードを活かせません。
この章では、現場が迷わず、「NG」を判断し、安全に業務を遂行できるための明確なルールと実践ノウハウを説明します。
「個人情報」と「機密情報」の具体的な境界線 AIに入力してはいけない情報の線引きを曖昧にしていると、誤入力のリスクが高まります。一般業務で扱う情報を「個人情報」と「機密情報」の二軸に分類し、判断基準を全社で統一することが重要です。
情報カテゴリ 定義と判断基準 一般業務における入力NG例 個人情報 生存する個人を特定できる情報、または他の情報と容易に照合でき個人を特定できる情報。
顧客・取引先の氏名や連絡先
従業員のメールアドレス
個人の購入履歴やクレーム内容(氏名と紐づいている場合)
機密情報
企業の競争優位性に関わる、非公開の情報。漏洩により企業の信用失墜や経済的損失につながるもの。
未発表の新製品情報
非公開の営業戦略
競合他社分析レポート
契約書の具体的な条項
社内サーバーのアクセスキー
重要なポイントは、「その情報が一般に公開されているか否か」です。企業内部のみで扱う情報や、個人・企業の特定に結びつく非公開データは、生成AIへ入力してはいけません。もしデータに個人情報が含まれる場合は、「匿名化(個人を特定できないような加工)」が必須となります。
現場のNG事例 現場の「少しだけなら……」という油断や、「これは機密情報ではないだろう」という誤った判断が、重大な事故を引き起こします。各部門で起こりがちな「うっかりミス」の危険な入力パターンを知りましょう。
【例 営業報告書の要約シーン】
NG入力例: 特定顧客A社の極秘プロジェクトにおける未公開受注金額や成功要因リスク: 取引先の機密情報(プロジェクト名、金額)や顧客の個人情報がAIの学習対象になる可能性がある 以上の事例からもわかるように、「具体的な顧客・企業名」「未公開の製品コードや数値」「個人を特定できる情報」を含むテキストをそのままAIに入力する行為はリスクが伴うため、いかなる場合でも入力をしないよう徹底してください。
コピペで安全に!機密情報を完全に排除するプロンプト設計術 人的ミスによる機密情報の漏洩を防ぐため、入力データから機密情報を自動的に排除し、抽象化された情報だけを安全に利用するためのコピペ可能な「機密情報自動排除プロンプトの型」をご紹介します。
機密情報自動排除プロンプトの型 この指示は、AIに「セキュリティ担当者」の役割を与え、厳格なデータ処理を要求します。以下のプロンプトをデータの先頭に加えてください。
あなたは機密情報と個人情報を厳格に管理するデータ処理AIです。
以下の【排除すべき情報の定義】に該当するすべての情報を、具体的な名詞を使わずに**「[特定情報A]」「[顧客情報]」**といった汎用的な記号に置き換えてください。
その上で、後続の【入力データ】を分析・要約してください。
【排除すべき情報の定義】
- 企業名、人名、メールアドレス、電話番号、具体的な金額(〇〇円)
- NDA(秘密保持契約)で保護されている情報、未発表の製品名やコードネーム
- 個人の識別につながるすべての情報
---
【入力データ】
(ここに要約したい営業レポートや開発議事録のテキストを貼り付けます) コピーする 編集する この型の最大のメリットは、AIに「機密情報を排除する役割(セキュリティ担当者)」を与え、「具体的な排除ルール」を指示することで、漏えいリスクを最小限に抑え、タスクを実行できる点にあります。
AIによる情報漏えいの仕組みと「企業が被った」具体的被害事例 あなたの入力データが学習される?情報流出のメカニズム 一般向けの生成AIでは、ユーザーの入力データ(プロンプトと回答)が、AIモデルの改善・再学習に使用される可能性があります。
情報流出は、この「学習」のプロセスが引き起こすリスクです。
【情報漏洩のメカニズム】
機密データの入力: ユーザーが誤って機密情報(例:新製品の設計データ)を入力学習データとして利用: 入力データはAIサービス提供元のサーバーに送られ、サービスの改善やモデルの学習データとして一時的に利用される情報漏えいの発生(再出力のリスク): 学習データに含まれた機密情報が、他のユーザーからの類似の質問(例 競合他社の製品に関する質問)に対する回答の一部として誤って出力されてしまう可能性がある このリスクは、技術的なバグだけでなく、AIの根本的な学習メカニズムに起因するため、特に企業利用においては、この学習プロセスを排除する対策が不可欠です。
会社を揺るがした情報漏洩の深刻事例 情報漏えいが企業に与える影響は甚大です。リスク対策の必要性を社内で共有するために、実際に起きた深刻な被害事例を把握しておきましょう。
1. Samsung Electronics(2023年)
概要: 半導体部門の社員が社内情報(ソースコードや会議録)を外部の生成AI(ChatGPT)へ入力した事案が確認された [1][2][3]。結果: 同社は2023年5月、社内デバイスや内部ネットワーク上での生成AI利用を禁止すると発表 [1][2]。教訓: 外部生成AIへの入力は実質的に“社外送信”であり、利用ポリシーの明確化とDLP等の技術的統制の併用が必要 [2]。 2. Microsoft(2023年)
概要: AI研究用GitHubリポジトリで過剰権限のSASトークンが公開され、最大38TBの内部データへアクセス可能な状態となっていた [4][5][6]。結果: 通報を受け、Microsoftはトークンを失効させる等の緩和措置を実施し、影響調査と再発防止策を公表(MSRC公式、2023年9月18日)[4]。教訓: 研究・開発資産の公開運用では、共有リンク権限の最小化と有効期限の短期化、公開前スキャンや鍵・トークン管理の標準化が不可欠 [4][5]。 参考
[1] Bloomberg, “Samsung Bans Generative AI Use by Staff After ChatGPT Data Leak ” 2023/05/02.
[2] TechCrunch, “Samsung bans use of generative AI tools like ChatGPT after April internal data leak ,” 2023/05/02.
まとめ
生成AIは、あなたの業務を変革する有用なツールですが、その活用は「安全性」という基盤の上に成り立たなければなりません。 「何を、なぜ入力してはいけないか」を明確にしたルールを設け、法人向けAIサービス
本記事で紹介した具体的な知識と行動指針を基に、ぜひ「AI利用ガイドライン」の作成に着手してください。
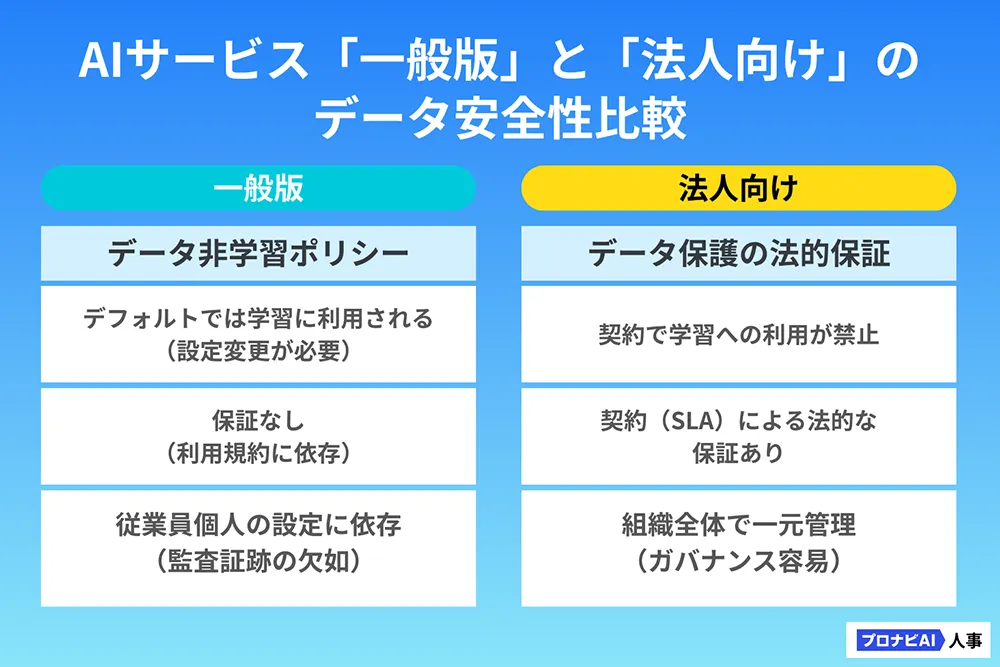
法人向けAIサービスと一般向けサービスの決定的な安全性の違い 機密性の高い業務にAIを本格導入する際は、法人向け(エンタープライズ)プランの導入が必須です。なぜ法人向けプランが安全なのかを解説します。
リスク回避の要はデータ非学習ポリシー 法人向けプランの最大の特徴は、契約レベルで「データ非学習ポリシー(Data Non-Training Policy)」が保証されている 点です。
法人向けサービスでは、入力データがAIモデルの学習に利用されないことが契約によって担保されます。これは、企業が最も懸念する「入力した情報が第三者への回答として漏えいする」という根本的なリスクを契約で排除できる
一般版で使える「オプトアウト機能」の設定手順とそのリスク 法人向けプランを導入するまでの暫定措置として、一般版に用意されている「オプトアウト機能」(入力データをAIの学習に使用しない設定)を利用する方法があります。
【オプトアウト機能の基本的な設定手順】
AIサービスのアカウント設定画面(例:「Settings」や「...」メニュー)を開く
「データ管理」や「プライバシー」といった項目に進む
「会話履歴を学習に使用する」などの項目を「オフ」に切り替える
【オプトアウト機能のリスク】 この機能は個人利用には有効ですが、企業利用には以下の重大な限界があります。
監査証跡の欠如: 従業員一人ひとりが設定を行うため、誰が、いつ、正しく設定したかという組織的な管理・証跡の確保が困難契約による保証の不在: あくまでツールの設定に依存するものであり、データ保護に関する法的責任(SLA)は法人契約ほど強力ではない したがって、全社的な安心感とガバナンスを確保するためには、速やかに法人向けサービスまたはAPI利用へと移行し、契約に基づくデータ保護 を確立することが必要です。
「個人情報保護法」の結論と法的リスク 次に、法律論ではなく「実務でどう行動すべきか
プロンプト入力は「第三者提供」にあたる?法解釈の結論 個人情報保護法における最大の論点は、「個人情報を含むデータをAIに入力する行為が個人データの第三者提供にあたるか 」という点です。
【法解釈の結論】 原則として、氏名などの個人情報を含むプロンプトを一般版AIに入力する行為は、「第三者提供」にあたります。
AIサービス提供事業者は、契約がない限り「第三者」と見なされます。この第三者に個人情報を提供する場合、個人情報保護法に基づき、情報主体(個人)の同意を得るか、所定のオプトアウト手続きを行う必要があります。
実務で取るべき安全かつ現実的な行動は、以下のいずれかです。
匿名化の徹底: AIに入力する前に、氏名や連絡先などの個人情報を完全に削除・匿名化する法人契約(委託)の利用: AIサービス提供事業者をデータ処理の「委託先」とみなし、契約によりデータ管理を厳格化できる法人向けサービスを利用する
グローバルで通用する「越境移転規制」へのシンプルな対応策 海外ベンダーのAIサービス(例:OpenAI、Googleなど)を利用する場合、データが海外のサーバーへ移動するため、日本の個人情報保護法に加え、「越境移転規制」への対応が求められます。
【シンプルな対応策】 データ保管場所の保証がある、法人向けAIサービスを導入することです。
法人向けプランは、多くの場合、EUの「EU一般データ保護規則(General Data Protection Regulation)」など国際的なプライバシー規制に対応するために設計されており、契約内でデータの保管場所(例:日本国内、または安全性が担保された地域)や国際的なデータ保護基準への準拠が保証されます。この契約上の保証を得ることが、複雑な越境移転規制への最もシンプルな対処法となります。
リスクを管理し、全社に浸透させるAIガバナンス構築 個人のリスク管理に依存するのではなく、全従業員が安全にAIを活用できる「仕組み」を企業側が作ることも大切です。
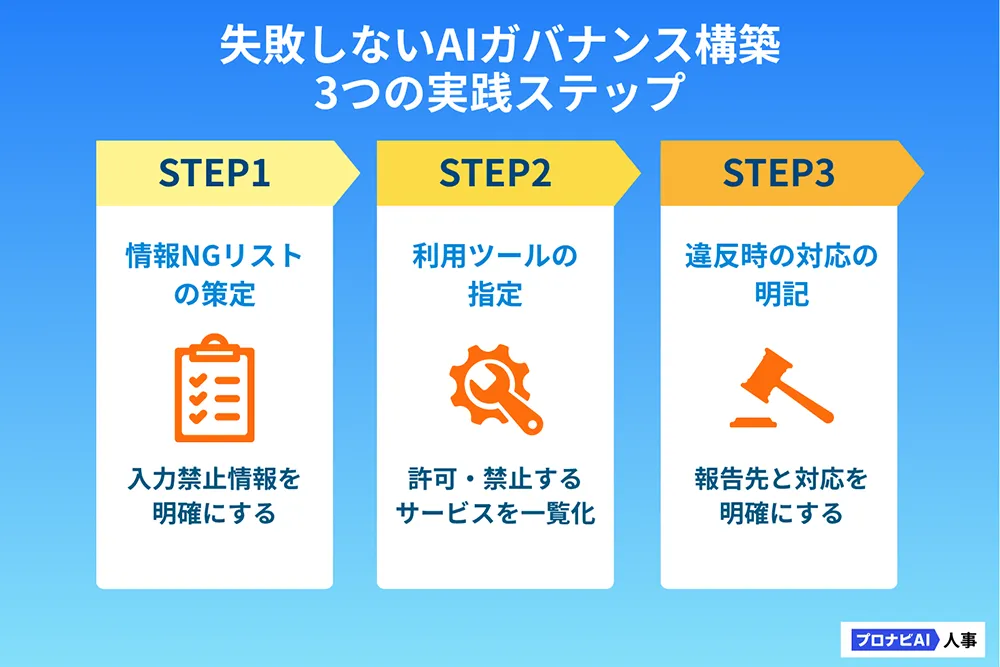
AI利用ガイドライン策定 AIガバナンス構築の第一歩は、従業員がすぐに参照できる「AI利用ガイドライン」の策定です。まずは「情報漏えいを防ぐ」ことに特化し、シンプルで具体的な内容で始めましょう。
【ガイドライン作成の3ステップ】 本記事の第一章に記載した「情報の境界線」を参考に、「絶対に入力してはいけない情報(氏名、未公開の数字、契約書など)」の具体的なリストを定義します。
「利用を許可するAIツール(例:法人契約のCopilot for Microsoft 365など)」と「禁止する一般版サービス」を一覧化します。
ルール違反が発生した場合の緊急報告先、および懲戒規定などの対応を明確に記述し、コンプライアンス意識を高めます。
目的: 企業の機密保護と生産性向上入力禁止情報: 具体的なNGリスト利用可能サービス: 法人プラン名と利用の前提条件違反時の報告先と対応: 緊急連絡先と取るべき行動
失敗しない従業員教育 ガイドラインは作っただけでは機能しません。従業員の行動に落とし込むためには、具体的な事例に基づいた「ケーススタディ」が最も有効です。
【ケーススタディの実施方法】
具体的な事故事例の提示: 先述の「深刻事例」のような他社での事故例を提示し、「もし自社で起こったらどうなるか」を想像させる。「その時どうする?」の議論: 参加者に「もしあなたが新製品の設計データの一部を要約する必要があったら、どの情報をどう加工して入力するべきか」を具体的な業務シーンに合わせてディスカッションを行う。安全なプロンプトの演習: 「機密情報自動排除プロンプトの型」を実際に利用させて、安全なデータ処理方法を体感してもらう。 ルールの伝達だけではなく、「今後取るべき行動」に焦点を当てた実践的な教育を通じて、全従業員のセキュリティ意識とAI活用スキルを向上させましょう。
生成AIに個人情報を入力するのは情報漏洩リスクにつながる?匿名化・非学習・法人契約による対策も徹底解説 | プロナビAI人事